
前言
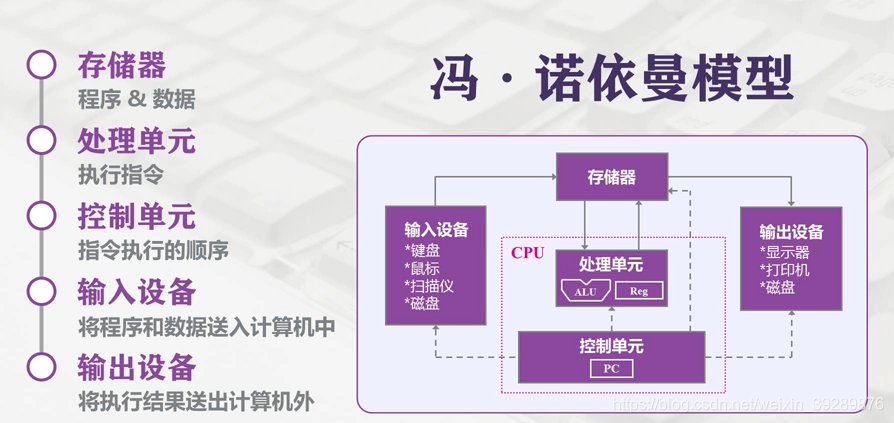
现在的计算机依然沿用的的是冯诺依曼结构,在此结构中储存器是关键环节,持久化数据和计算数据空间都依赖这存储器,在理想的状态下,存储器应该具备以下特性
- 速度要非常快,至少要跟上CPU执行一条命令的速度,这样CPU的效率才有无限的返回空间,不会受限于存储器
- 容量应该足够大,在数字化时代中,需要持久化下来的数据越来越多,数据的存储应当不受容量的限制
- 价格足够便宜,价格低廉,所有类型的计算机都能配备或者说能够达到民用级别覆盖大多数人
分层存储器结构
现实上真的有这种理想的存储器吗,我们目前的芯片产业技术无法同时满足上述所有条件,其实大部分还是限制于成本的考量,于是现在计算机都采用如下的分层次存储器模式结构

从上到下
-
存取速度最快的是寄存器,因为寄存器就封装在CPU里面,并且制作材料和CPU是相同的,所以速度可以和CPU相同,CPU访问寄存器几乎是没有延迟,但是大家都说CPU是人类制造业巅峰造极的结晶,寄存器因为价格昂贵,因此容量非常小,一般cpu配备的寄存器容量都是bit级别的,仅存放CPU的指令。
- 其次的是cpu多级缓存,也称高速缓存。现在英特尔和AMD都配备三级,分别是L1,L2,L3。一般L1是cpu独显的moment,L3采用共享模式,L2不同的处理器厂商有不同的设计处理, 英特尔民用酷睿L2采用共享模式,AMD民用锐龙采用独显的模式。这部分也是封装在cpu内部,容量也比较小,L1和L2通常KB级别,L3可达到MB级别。目前英特尔十一代酷睿i5-11400的L3是12MB, AMD的五代锐龙5600x的L3是32MB(小声~amd yes)
- 然后是大家比较熟悉的内存,内存是计算机的主存,通常也叫随机访问存储器。它也是直接和CPU交换数据的内部存储器,它可以随时读写并且速度很快,但是它是易失性存储,断电就会丢失数据。这部分容量可以定制,就是大家常说的加内存条,通常是GB级别。
- 最后是磁盘,磁盘和主存相比速度大概慢了三个数量级,因此成本会低很多,容量也会随之大很多,动辄就TB或者三位数的GB。固态使用的硅芯片半导体的存储,机械硬盘采用机械臂加磁头去读取金属片盘扇区。

主内存
内存是操作系统进行i/o操作的重中之重,绝大部分的工作都是在用户进程和内核缓冲区完成的,因为内存速度相对于磁盘来说会快一些,相对于cpu缓存来说容量大一些,所以接下来需要了解一些内存相关的知识
物理内存
物理内存就是真实的上述所说的第三种外存,它插在主板上用来加载各式各样的程序以及数据来供cpu读取
虚拟内存
这为什么引出一个虚拟内存的概念,从计算机组成上来说,物理内存就是加载各种应用程序的存储器,但是从操作系统角度来说,直接操作物理内存有很多局限性。因为应用每次申请内存需要一整块连续的区域,会导致下面的情况,刚开始逐个打开应用,应用把物理内存都占满了,然后我想玩游戏了,我需要保留微信和朋友语音和打开网易云听歌,qq和b站可以杀死,但是因为中间网易云隔开了,导致王者荣耀需要占用一整块连续的内存空间无法满足。这样就会有假满的情况,这样显然是不合理的。

于是,引出了虚拟内存的概念,虚拟内存的核心原理是:为每个程序设置一段”连续”的虚拟地址空间,把这个地址空间分割成多个具有连续地址范围的页 (page),并把这些页和物理内存做映射,在程序运行期间动态映射到物理内存。当程序引用到一段在物理内存的地址空间时,由硬件立刻执行必要的映射;而当程序引用到一段不在物理内存中的地址空间时,由操作系统负责将缺失的部分装入物理内存并重新执行失败的指令。
虚拟地址空间按照固定大小划分成被称为页(page)的若干单元,物理内存中对应的则是页帧(page frame)。这两者一般来说是一样的大小,如上图中的是 4KB,不过实际上计算机系统中一般是 512 字节到 1 GB,这就是虚拟内存的分页技术。因为是虚拟内存空间,每个进程分配的大小是 4GB (32 位架构),而实际上当然不可能给所有在运行中的进程都分配 4GB 的物理内存,这里还会使用一个叫swapping的技术,在进程运行期间只分配映射当前使用到的内存,暂时不使用的数据则写回磁盘作为副本保存,需要用的时候再读入内存,动态地在磁盘和内存之间交换数据。

这样有一个好处就是,用户程序申请的内存是虚拟内存,这虚拟内存映射物理内存时,这个物理内存可以不连续,然后我们要引出一个内存管理单元(Memory Management Unit,MMU), 当需要访问虚拟内存其实cpu会把这些虚拟地址通过地址总线发送给MMU, 然后MMU将这个虚拟地址映射成物理地址后再通过内存的总线去访问物理内存。
最后,还需要了解的一个概念是转换检测缓冲器(Translation Lookaside Buffer,TLB),也叫快表,是用来加速虚拟地址映射的,因为虚拟内存的分页机制,页表一般是保存内存中的一块固定的存储区,导致进程通过 MMU 访问内存比直接访问内存多了一次内存访问,性能至少下降一半,因此需要引入加速机制,即 TLB 快表,TLB 可以简单地理解成页表的高速缓存,保存了最高频被访问的页表项,由于一般是硬件实现的,因此速度极快,MMU 收到虚拟地址时一般会先通过硬件 TLB 查询对应的页表号,若命中且该页表项的访问操作合法,则直接从 TLB 取出对应的物理页框号返回,若不命中则穿透到内存页表里查询,并且会用这个从内存页表里查询到最新页表项替换到现有 TLB 里的其中一个,以备下次缓存命中。
io缓冲区
因为后续会介绍io,趁着介绍内存,顺带提一个缓冲区。linux的read()和write()是最基本的io系统调用,这两个系统调用之间会存在一个缓冲区,所谓的io缓冲区就是在内核空间(下次会介绍)与磁盘网卡等外设之间的一层缓冲区,用来提升读写的性能。
传输中比较常见是内核缓冲区-Kernel Buffer Cache(从磁盘读取)和Socket Cache(将写入网卡),前者是Page Cache和Buffer Cache的统称,值得注意的是Page cache大家喜欢称为磁盘高速缓存, 但是这部分的存储器是内存,虽然它名字中有磁盘两个字……。
为什么会有这个磁盘高速缓存,因为读写内存比读写磁盘快得多,如果能把读写磁盘换成读写内存,那效率会提升非常多,如果内存和硬盘空间成本是一样的话,那就没这么多烦恼了,可是现实是残酷的。但是我们程序运行的时候其实具有局部性的,意思是每次其实不需要访问所有的数据,并且通常来说是存在热点数据的,或者说刚才被访问的数据短时间内被访问的概率很高,所以操作系统设计者设计出磁盘高速缓存来缓存最近被访问的数据,当空间不足时使用LRU来淘汰最久未被访问的缓存。
具体流程是,读磁盘数据的时候,优先在pageCache看一下,如果数据存在则直接返回,如果没有,则从磁盘中读取,然后缓存在PageCache中供下次读取。大量研究表示刚刚读取的数据相邻数据块接下来被读到的概率非常大,所以pageCache提供预读功能每次偷偷多读一点,反正如果长时间没有访问会被淘汰掉,如果命中了数据,收益会非常大。
基于上面所介绍的,大家不难想到PageCache的缺点,以上收益都基于小文件读取的情况下(通常是程序运行数据), 假如io的文件非常大,其实PageCache收益就不高,因为文件很大磁盘高速缓存空间很快就会被塞满,然后淘汰塞满然后淘汰,因为文件太大,数据被再次访问的概率非常低,因为频繁的淘汰写入不仅没有任何的时间收益反而还会带来性能问题(大文件通常是GB级别的)。
这里补充一个Buffer Cache, 实际上Page Cache 是基于虚拟内存的页单元缓存,而Buffer Cache 是对粒度更细的设备块的缓存,也就是说其实每次读取拷贝数据会有两份备份,冗余且低效。更可怕的会导致可能存在不一致问题,为了规避这个问题,所有基于磁盘文件系统的 write,都需要调用 update_vm_cache() 函数,该操作会把调用 write 之后的 Buffer Cache 更新到 Page Cache 去。由于有这些设计上的弊端,因此在 Linux 2.4 版本之后,kernel 就将两者进行了统一,Buffer Cache 不再以独立的形式存在,而是以融合的方式存在于 Page Cache 中。因为经常会so看到有人讨论下图buff/cache,其实这部分就是Page Cache和Buffer Cache的统称, 它们其实已经在一块位置了,所以不需要纠结。

后言
然后内存知识里面其实有非常多的内容,比如多级页表,倒排页表,以及页面置换算法,因为篇幅问题以及侧重点问题本文最多就讲到这里了,内容少一点理解起来方便一些,希望对大家有一点帮助。
本博客所有文章除特别声明外,均采用 @Oreoft 许可协议。转载请注明出处!
┌┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┐
├ 记得关注公众号:没有气的汽水 ┤
└┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┘
