
Preface
Background
This post will introduce a library I wrote myself, library address here, the main role is to provide an annotation, use this annotation in your method, the library provides functionality will help you automatically cache the data, the next time you call this method as long as the input parameter is the same as the direct will be from the cache! The next time you call the method, as long as the input parameter is the same, you will get the data directly from the cache, and you will not execute the method again (the content of the method may be to go to the DB or PRC).
The reason for writing this library is that there is a similar tool within the company , at first did not Get to it has much use , as in the company to contact more business needs , found that this is really too usefull . And I have some of my own more ideas about it , so I intend to write their own open source out on the one hand can be used for their other open source projects , on the other hand, I think there are the same needs of the people are quite a lot , and Github does not have a perfect similar libraries.
Different levels of volume of users of the code is really different, I also do in the last company is also the C end of the business, for the use of cache, although very much, but mainly the use of Redis data structure features to do some business implementation will be more, for example, using string to do mutual exclusion lock/configuration switches/status logging, using zset to do the list/realization of the needs of the dmq, list/set/hash to do high-performance short-term database. set/hash to do high performance short duration database. For a lot of DB data are directly check, the main product at that time the user volume is very smooth, took the financing of the time the company has money, the database with a very good, from the library is also a lot of online do not need to pressure test, No requirement for RTT of the interface.
But now the company, the C-terminal interface are done to limit the flow, in addition to paging data almost all the data to add a layer of cache, and even the first page of the paging data will be done. This is very troublesome, every time you have to write a lot of repetitive code, take the value from Redis, empty away on the DB/RPC, and then write back to Redis. the most horrible is the batch fetch value, from Redis to get after the hit after the batch out of the no hit and then go to DB/RPC fetch, and then write back to the value of this part of the Redis. because of the user volume is very large, and there is a wool party will brush the interface, the value of the no hit, may also need to do empty cache to prevent penetration to the DB. may also need to do empty cache to prevent penetration into the DB.
Contains
This repository contains the following:
- @Cache annotation
- Automatically cache the specified method
- It can automatically cache non-existent data to prevent cache penetration under concurrency
- Automatic mutex lock can be enabled when acquiring cache to prevent cache breakdown and protect DB
Functions similar to Spring-cache, I think this library is much better than Spring-cache, first of all Spring-cache does not support the key for each write to set a separate expiration time, which Gives me good reason not to use it; and then EL expression on the cost of getting started is also very high, but it implements the function of the function is very simple and senseless function, I think that this is the same as Spring’s own convention over configuration contrary to this library provides four types (described below) allows you to follow the convention to reduce the configuration, the simplest only need to provide prefix can be used. I think this and Spring’s own convention over configuration contrary to what this library provides four types (described below) allows you to follow the convention to reduce the configuration , the simplest only need to provide prefix can be used . Spring-cache also does not support the bulk query process to query only the incremental data , also does not support the empty cache , also does not support the anti-penetration …..
how-to-import
This library has been put on the maven central warehouse, only need to import the pom file of the project. Please note that version 1.x.x are testing version and cannot work properly
For all version queries click HERE HERE HERE
Maven
<!-- https://mvnrepository.com/artifact/cn.someget/cache-anno -->
<dependency>
<groupId>cn.someget</groupId>
<artifactId>cache-anno</artifactId>
<version>2.0.0</version>
</dependency>
Gradle
// https://mvnrepository.com/artifact/cn.someget/cache-anno
implementation group: 'cn.someget', name: 'cache-anno', version: '2.0.0'
There is no configure need to for this library, all beans are exposed through spring.factories and can be directly scanned by the startup class.
How-to-use
Notes
-
This library relies on spring’s auto-assembled redis or manually assembled redisTemplate, and the configuration supports jedis and lettuce.
-
The data stored using this annotation is serialized as String, and of course, the automatic read data deserialization of annotations is also String. If you use annotations to store data, but do not use annotations to read data, please use String deserialization to read.
-
All redis io exceptions have been captured, and the exceptions will be printed to the log, which will not pollute the business code, will not affect your data reading, and will eventually read data from the db
Usage
1. Getting Started and Principles
// It is recommended to define the prefix as a constant for easy reuse. One to one does not need to pass the clazz parameter
@Cache(prefix = "user:info:%d")
public UserInfoBO getIpUserInfo(Long uid) {
UserInfo userInfo = userInfoMapper.selectByUid(uid);
if (userInfo == null) {
return null;
}
UserInfoBO bo = new UserInfoBO();
BeanUtils.copyProperties(userInfo, bo);
return bo;
}
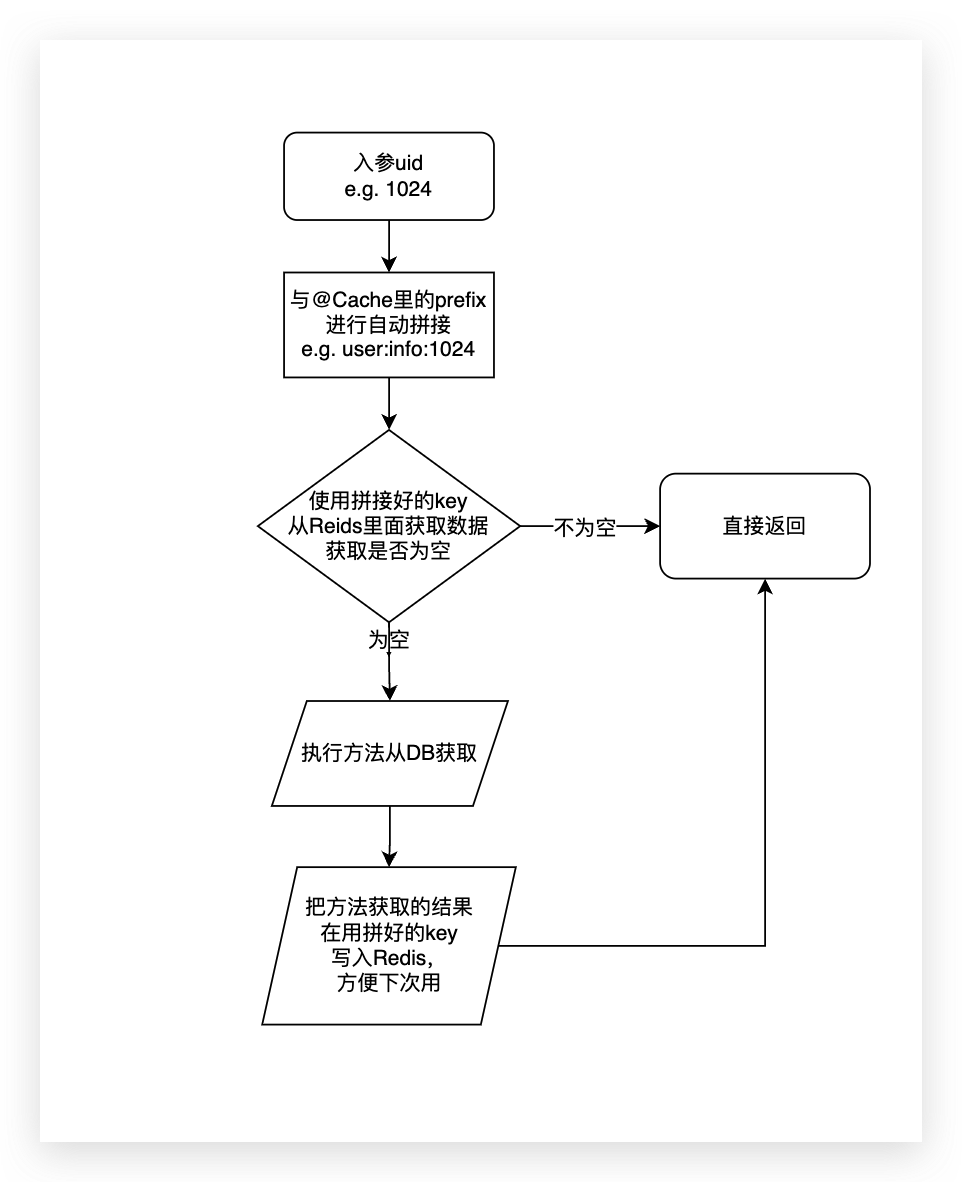
If the above method is not annotated with @Cache, it is a simple method to query user information from the user table via uid, but it is still such a simple method after adding @Cache.
Before the query, the parameter uid will be spliced according to the prefix in the annotation, and then try to get data from Redis.
If the execution function does not hit the cache, it will be automatically written to the cache after the execution is completed.
The next time this function is executed, the prefix splicing parameter will be executed and the data will be tried to obtain from Redis. Because it was written automatically last time, the data will be returned directly, and the function will not be executed again.
2. advanced comprehension
// The return value is a collection type, clazz must be passed
@Cache(prefix = "mall:item:%d", clazz = MallItemsBO.class)
public Map<Long, MallItemsBO> listItems(List<Long> itemsIds) {
BaseResult<List<MallItemsDTO>> result = itemsRemoteClient.listItems(new ItemsReqDTO());
if (result == null || CollectionUtils.isEmpty(result.getData())) {
return Collections.emptyMap();
}
return result.getData().stream()
.map(mallItemsDTO -> {
MallItemsBO mallItemsBO = new MallItemsBO();
BeanUtils.copyProperties(mallItemsDTO, mallItemsBO);
return mallItemsBO;
}).collect(Collectors.toMap(MallItemsBO::getItemId, Function.identity()));
}
The method is not annotated with @Cache. It is a function to remotely obtain item details from other services in batches through itemId.
When @Cache is added, it is still the original method. Before the query, all itemIds in the parameters and the prefix in the annotation will be spliced together, and then the results will be obtained from redis at one time. If all itemIds are obtained, they will be returned directly.
If there is an itemId that is not hit, the missed itemId will be unified and used for remote fetching. Finally, the summary in Redis (the remote fetching will be automatically written to the cache)

3. Supported method types
| type | prefix | input | output | remark |
|---|---|---|---|---|
| one to one | custom: placeholder | wrapper type or String | ? extends Object | The number of input parameters is equal to the number of placeholders |
| ont to list | custom: placeholder | wrapper type or String | List<? extends Object> | The same as above, in theory, List and object are same thing for this library, because I use String serialization |
| list to map_one | custom: placeholder | List |
Map<Input wrapper type or String, ? extends Object> | If it is a batch query, the first input parameter must be the corresponding query List. Each element in the list will be spliced with the prefix, so the placeholder of the prefix is the placeholder corresponding to the element in the list. |
| list to map_map | custom: placeholder | List |
Map<Input wrapper type or String, List<? extends Object» | This type is actually the same as above. Each element in the type List corresponds to an object. Each element of this type List corresponds to a list. I deserialize the same. Due to the limitation of java’s generic erasure, it is impossible to determine what the value generic of Map is. Please set the parameter hasMoreValue in @Cache to true |
Placeholders should be noted that the string type requires the placeholder is %s, the integer placeholder is %d, and the floating-point placeholder is %f Please refer to here for details
The summary is divided into two categories. The input parameter is an object or a List, that is, a single acquisition and a batch acquisition. If it is a batch acquisition, remember that the List must be No. 1, and the method input parameters cannot exceed two, otherwise the unsupported method will be thrown. abnormal.
4. The meaning of the parameters in the annotation
| name | meaning | remarks |
|---|---|---|
| prefix | The prefix of the key in Redis | To use a placeholder, if the input parameter is long, the placeholder is prefixKey:%d |
| expire | Expiration time (in seconds) | If you do not set the expiration time when using annotations, the default is 10 minutes. Note that the expiration time is enabled by default in the write cache of this library. |
| missExpire | Empty cache expiration time (in seconds) | If it is 0, it means that the empty cache is not enabled (the default is 0). The expiration time of the empty cache means that if the result is not found from the db, an empty cache will be generated to Redis. The expiration time of this empty cache (the normal cache must be short, recommended 3- 10 seconds) |
| hasMoreValue | Whether list to map_map type | Due to the limitation of generic erasure in java, it is impossible to determine what the value generic of Map is. Please set the parameter hasMoreValue in @Cache to true |
| clazz | Collection class return value corresponding type | If the return value is List or Map, this must be passed, because java generic erasure leads to inability to perceive the generic type of the collection, and deserialization needs to be used. If it is a one to one type, this can be omitted. |
| usingLocalCache | Whether to use local cache | After setting true, the local cache (using caffeine) will be queried before reading from Redis. Similarly, the data will be written back to caffeine after taking it. |
5. Detailed description of other functions
Enable empty cache writes
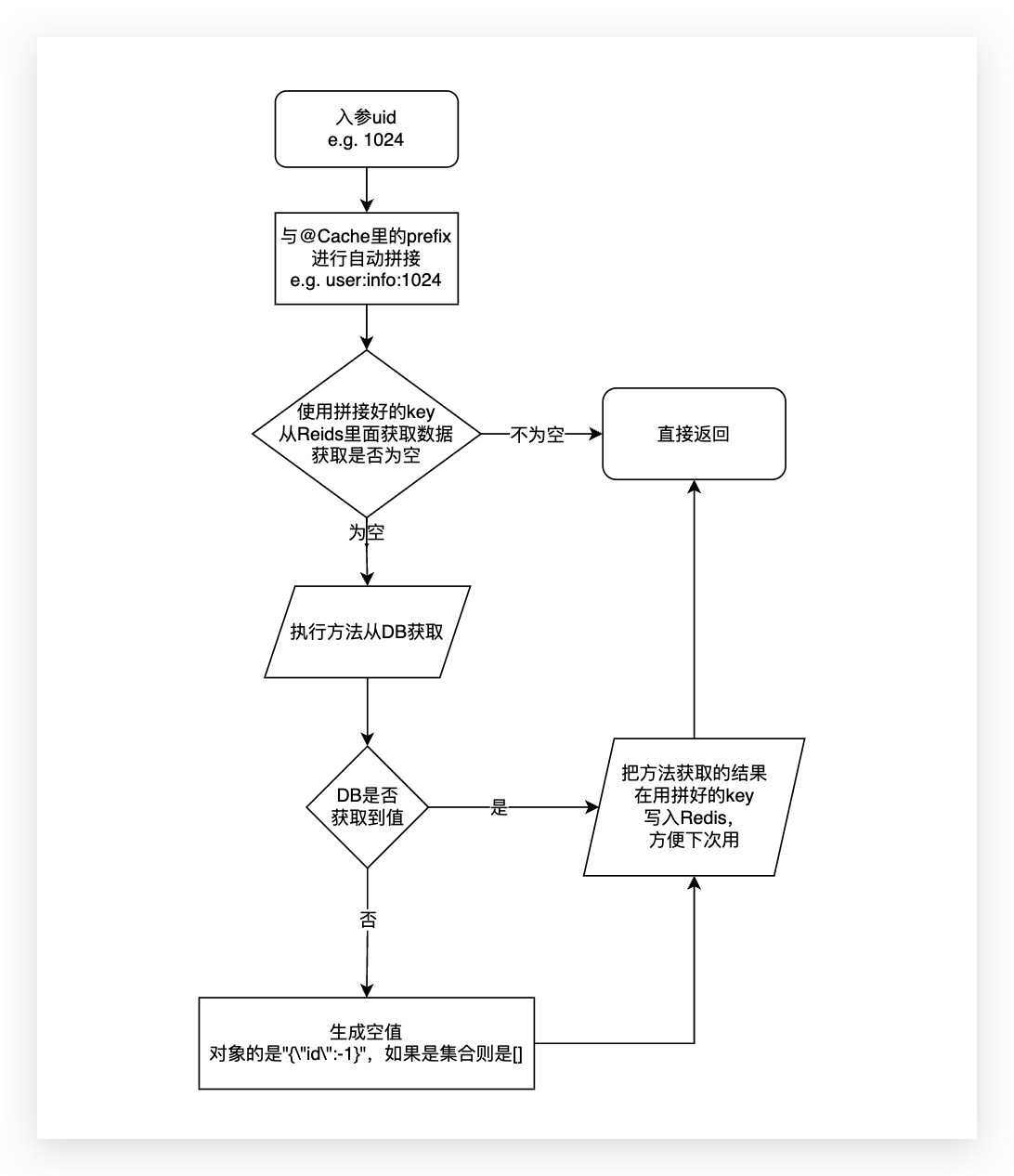
@Cache contains the attribute missExpire. The meaning of the attribute is the expiration time of the value that does not exist in the DB (in seconds).
The default value is 0. If it is 0, it means that if the value of the query does not exist in the DB, no empty cache processing will be performed.
If it is not 0, then the query value from Redis will not be hit, and the method query will be performed. If the method query returns no result,
a null value will be stored (if it is an object, it is "{\"id\":-1}" , if it is a collection, it is []), the expiration time is the value of missExpire (recommended 3-10 seconds),
and all types in the table are supported.
Note:
- After the empty cache is enabled, the cache processing needs to be deleted after inserting records, because the corresponding value may already exist in the DB, but there is still an empty value in Redis that is in the TTL.
If the empty cache is an object, it will cache an object with an id of -1. If it is a collection, an empty collection will be cached. An object with an id of -1 will not be returned to the method caller and will be filtered out directly, which is in line with your coding habits. It should be noted that the cache object must have an id field (both Integer and Long), otherwise it cannot be filtered, which will return an empty object with all properties null.Version 2.0.1 or later supports setting the object empty cache to"{}", so it does not have to contain an id. The caller of the method that hits the empty cache will get null, which is in line with everyone’s coding habits. All empty cache objects must be constructed without parameters, otherwise deserialization cannot generate empty objects.
enable local cache
@Cache contains the attribute usingLocalCache, which means enable local cache or not,
In e-commerce marketing, commodity data is frequently obtained through RPC, because the QPS of the marketing scenario is very high. Even if there is Redis before RPC, the frequent acquisition of commodities leads to a very high QPS of Redis.
The product data does not change very much, so it is necessary to add a local cache before redis, which will reduce the qps of redis
There are many scenarios where using local cache will reduce qps.
This library supports local caching. Just use the annotation to set the attribute of usingLocalCache to true (default is false).
The local cache used by this library is caffeine, which has recently overwhelmed Guava. , so that the local cache is queried before getting the data, and if the local cache does not hit, then Redis is queried.
Note: Multi-layer caching will increase the possibility of Cache-DB inconsistency. Here, the default TTL of the local cache is 3 seconds, and modification is not supported for the time being.
Post-word
next-steps
- Improve unit testing, welcome everyone to pr
- There are already good solutions to prevent cache breakdown, and the next version will merge
- Evicting the cache using annotations
Your joining is very welcome! New Issue or Pull Request.
(Retrieved from this site with permission of the author and source Oreoft))
Post Directory
Here is the comment section, welcome to leave a message to discuss or point out mistakes hhhh