
前言
redis是一个nosql的存储系统,它是以key-value的形式存在内存中,所以性能非常高。提供了很多数据结构和多语言的api,所以玩法很多可以实现很多功能和需求,但是目前我在项目中接触功能到的非常有限。所以在b站看视频学习它的更多功能,希望有朝一日可以用到自己的项目当中。
这个帖子持续会更新学习的笔记,学习的视频来源是资料1中的B站视频,老师的PPT做的很好,而且言简意赅又出奇的全面,十分推荐。
因为内容过多redis笔记分成两部分,上篇学习了一些常用的redis命令和reids提供的最基本的数据结构以及存储和事务。期间也看到一些大牛写的文章,发现每种数据结构都可以玩出花来,例如居然还可以用list来做消息队列。很惭愧的是平时项目中使用很少会去仔细思考redis数据结构选择对于业务的影响。下面是我的下篇内容,我也将把每天的学习内容整理成笔记更新。
六、删除策略
1、数据删除策略
- 定时删除
- 惰性删除
- 定期删除
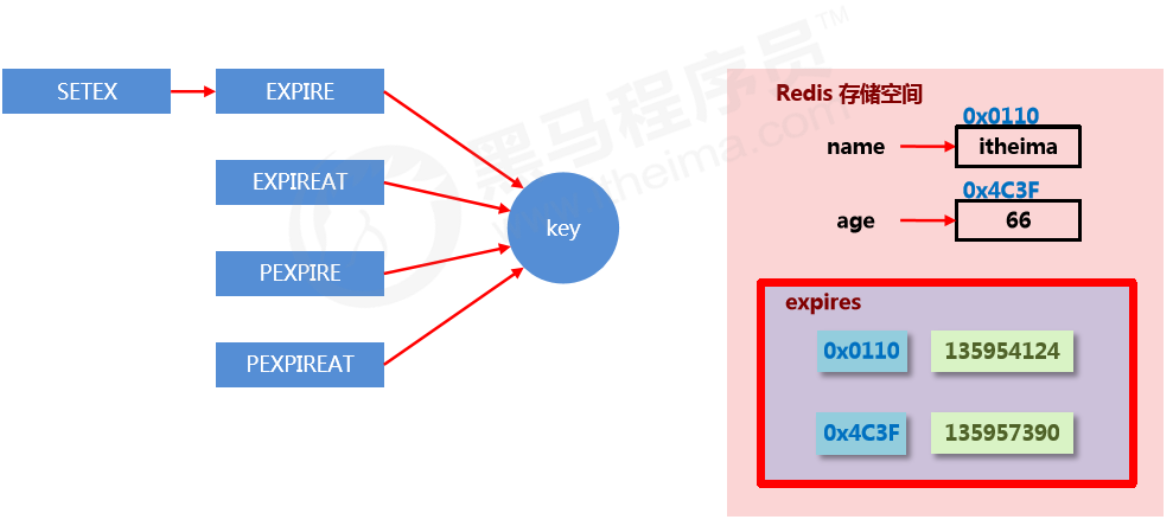
时效性数据的存储结构
- Redis中的数据,在expire中以哈希的方式保存在其中。其value是数据在内存中的地址,filed是对应的生命周期
数据删除策略的目标
在内存占用与CPU占用之间寻找一种平衡,顾此失彼都会造成整体redis性能的下降,甚至引发服务器宕机或内存泄露
2、三种删除策略
定时删除
- 创建一个定时器,当key设置有过期时间,且过期时间到达时,由定时器任务立即执行对键的删除操作
- 优点:节约内存,到时就删除,快速释放掉不必要的内存占用
- 缺点:CPU压力很大,无论CPU此时负载量多高,均占用CPU,会影响redis服务器响应时间和指令吞吐量
- 总结:用处理器性能换取存储空间 (拿时间换空间)
惰性删除
- 数据到达过期时间,不做处理。等下次访问该数据时
- 如果未过期,返回数据
- 发现已过期,删除,返回不存在
- 优点:节约CPU性能,发现必须删除的时候才删除
- 缺点:内存压力很大,出现长期占用内存的数据
- 总结:用存储空间换取处理器性能 (拿空间换时间)
定期删除

- 周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
- 特点1:CPU性能占用设置有峰值,检测频度可自定义设置
- 特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
- 总结:周期性抽查存储空间 (随机抽查,重点抽查)
3、逐出算法
**当新数据进入redis时,如果内存不足怎么办? **
- Redis使用内存存储数据,在执行每一个命令前,会调用freeMemoryIfNeeded()检测内存是否充足。如果内存不满足新加入数据的最低存储要求,redis要临时删除一些数据为当前指令清理存储空间。清理数据的策略称为逐出算法
- 注意:逐出数据的过程不是100%能够清理出足够的可使用的内存空间,如果不成功则反复执行。当对所有数据尝试完毕后,如果不能达到内存清理的要求,将出现错误信息。
影响数据逐出的相关配置
-
最大可使用内存
maxmemoryCopy占用物理内存的比例,默认值为0,表示不限制。生产环境中根据需求设定,通常设置在50%以上。
-
每次选取待删除数据的个数
maxmemory-samplesCopy选取数据时并不会全库扫描,导致严重的性能消耗,降低读写性能。因此采用随机获取数据的方式作为待检测删除数据
-
删除策略
maxmemory-policyCopy达到最大内存后的,对被挑选出来的数据进行删除的策略
影响数据逐出的相关配置

LRU:最长时间没被使用的数据
LFU:一段时间内使用次数最少的数据
数据逐出策略配置依据
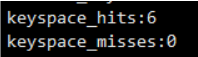
- 使用INFO命令输出监控信息,查询缓存 hit 和 miss 的次数,根据业务需求调优Redis配置
七、高级数据类型
1、Bitmaps
基础操作
-
获取指定key对应偏移量上的bit值
getbit key offsetCopy -
设置指定key对应偏移量上的bit值,value只能是1或0
setbit key offset valueCopy
扩展操作
-
对指定key按位进行交、并、非、异或操作,并将结果保存到destKey中
bitop op destKey key1 [key2...]Copy- and:交
- or:并
- not:非
- xor:异或
-
统计指定key中1的数量
bitcount key [start end]Copy
2、HyperLogLog
基数
- 基数是数据集去重后元素个数
- HyperLogLog 是用来做基数统计的,运用了LogLog的算法

基本操作
-
添加数据
pfadd key element1, element2...Copy -
统计数据
pfcount key1 key2....Copy -
合并数据
pfmerge destkey sourcekey [sourcekey...]Copy
相关说明
- 用于进行基数统计,不是集合,不保存数据,只记录数量而不是具体数据
- 核心是基数估算算法,最终数值存在一定误差
- 误差范围:基数估计的结果是一个带有 0.81% 标准错误的近似值
- 耗空间极小,每个hyperloglog key占用了12K的内存用于标记基数
- pfadd命令不是一次性分配12K内存使用,会随着基数的增加内存逐渐增大
- Pfmerge命令合并后占用的存储空间为12K,无论合并之前数据量多少
3、GEO
基本操作
-
添加坐标点
geoadd key longitude latitude member [longitude latitude member ...] georadius key longitude latitude radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]Copy -
获取坐标点
geopos key member [member ...] georadiusbymember key member radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]Copy -
计算坐标点距离
geodist key member1 member2 [unit] geohash key member [member ...]Copy
八、主从复制
1、简介
多台服务器连接方案
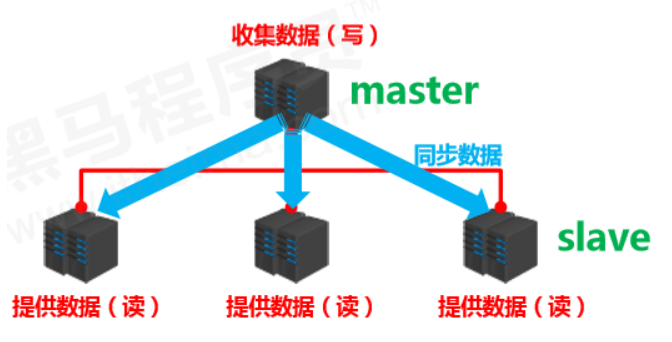
- 提供数据方:master
- 主服务器,主节点,主库
- 主客户端
- 接收数据的方:slave
- 从服务器,从节点,从库
- 从客户端
- 需要解决的问题
- 数据同步
- 核心工作
- master的数据复制到slave中
主从复制
主从复制即将master中的数据即时、有效的复制到slave中
特征:一个master可以拥有多个slave,一个slave只对应一个master
职责:
- master:
- 写数据
- 执行写操作时,将出现变化的数据自动同步到slave
- 读数据(可忽略)
- slave:
- 读数据
- 写数据(禁止)
2、作用
- 读写分离:master写、slave读,提高服务器的读写负载能力
- 负载均衡:基于主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量
- 故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复
- 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
- 高可用基石:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
3、工作流程
总述
- 主从复制过程大体可以分为3个阶段
- 建立连接阶段(即准备阶段)
- 数据同步阶段
- 命令传播阶段
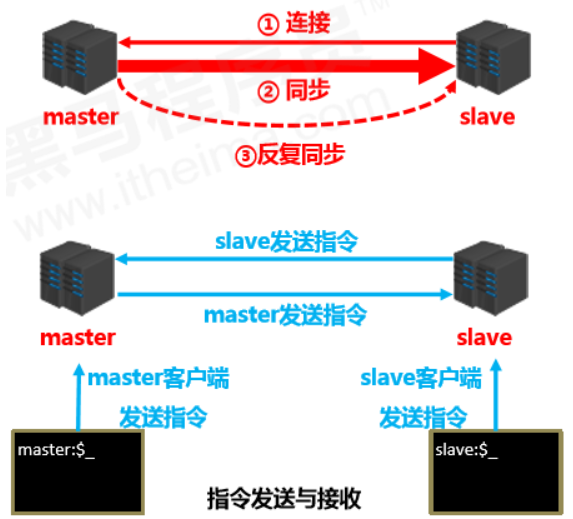
阶段一:建立连接
-
建立slave到master的连接,使master能够识别slave,并保存slave端口号
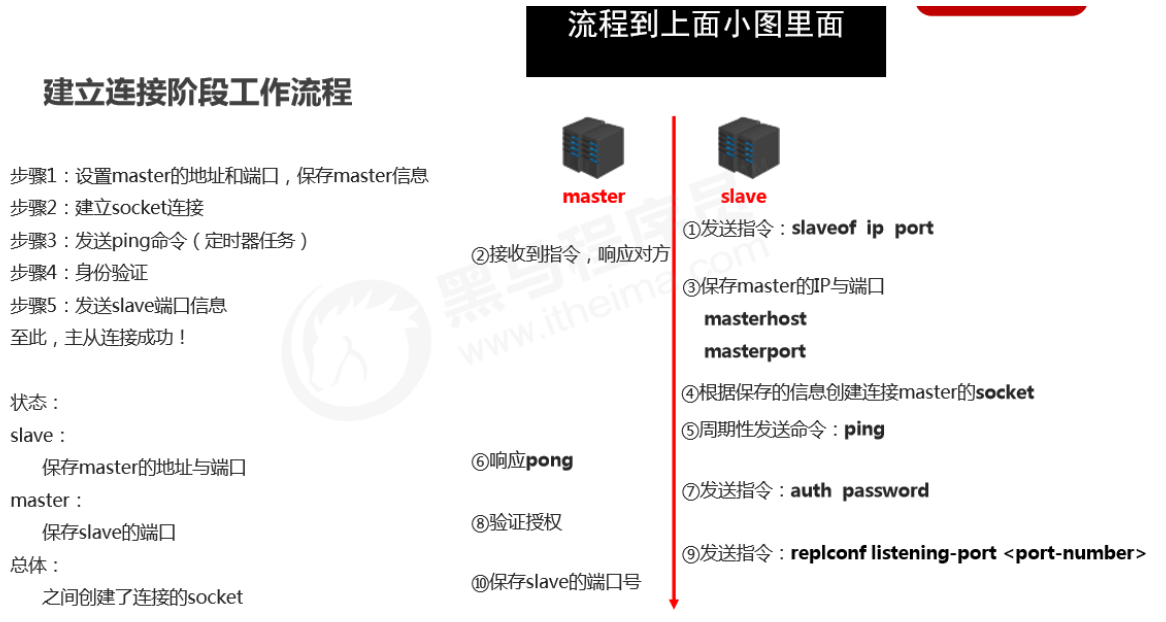
**主从连接(slave连接master) **
-
方式一:客户端发送命令
slaveof <masterip> <masterport>Copy -
方式二:启动服务器参数
redis-server -slaveof <masterip> <masterport>Copy -
方式三:服务器配置 (常用)
slaveof <masterip> <masterport>Copy
主从断开连接
-
客户端发送命令
slaveof no oneCopy- 说明: slave断开连接后,不会删除已有数据,只是不再接受master发送的数据
授权访问
-
master客户端发送命令设置密码
requirepass <password>Copy -
master配置文件设置密码
config set requirepass <password> config get requirepassCopy -
slave客户端发送命令设置密码
auth <password>Copy -
slave配置文件设置密码
masterauth <password>Copy -
slave启动服务器设置密码
redis-server –a <password>Copy
阶段二:数据同步阶段
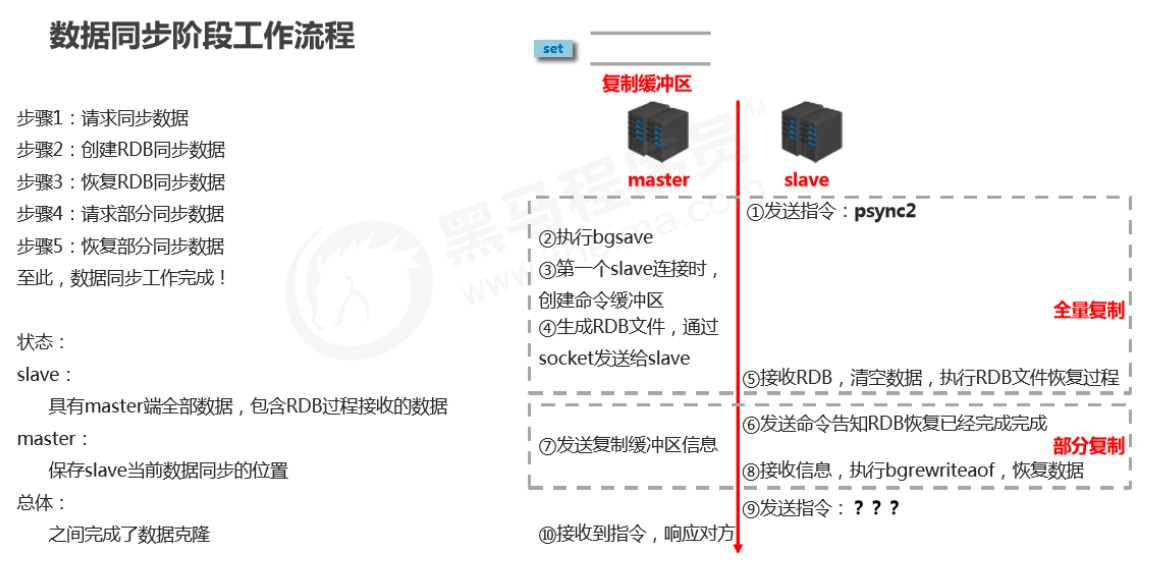
-
全量复制
- 将master执行bgsave之前,master中所有的数据同步到slave中
-
部分复制
(增量复制)
- 将master执行bgsave操作中,新加入的数据(复制缓冲区中的数据)传给slave,slave通过bgrewriteaof指令来恢复数据
数据同步阶段master说明
- 如果master数据量巨大,数据同步阶段应避开流量高峰期,避免造成master阻塞,影响业务正常执行
- 复制缓冲区大小设定不合理,会导致数据溢出。如进行全量复制周期太长,进行部分复制时发现数据已经存在丢失的情况,必须进行第二次全量复制,致使slave陷入死循环状态。
repl-backlog-size 1mbCopy
- master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,留下30%-50%的内存用于执 行bgsave命令和创建复制缓冲区
数据同步阶段slave说明
- 为避免slave进行全量复制、部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
slave-serve-stale-data yes|noCopy
- 数据同步阶段,master发送给slave信息可以理解master是slave的一个客户端,主动向slave发送命令
- 多个slave同时对master请求数据同步,master发送的RDB文件增多,会对带宽造成巨大冲击,如果master带宽不足,因此数据同步需要根据业务需求,适量错峰
- slave过多时,建议调整拓扑结构,由一主多从结构变为树状结构,中间的节点既是master,也是 slave。注意使用树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟较大,数据一致性变差,应谨慎选择
阶段三:命令传播阶段
- 当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作称为命令传播
-
master将接收到的数据变更命令发送给slave,slave接收命令后执行命令
- 主从复制过程大体可以分为3个阶段
- 建立连接阶段(即准备阶段)
- 数据同步阶段
- 命令传播阶段
命令传播阶段的部分复制
- 命令传播阶段出现了断网现象
- 网络闪断闪连
- 短时间网络中断
- 长时间网络中断
- 部分复制的三个核心要素
- 服务器的运行 id(run id)
- 主服务器的复制积压缓冲区
- 主从服务器的复制偏移量
服务器运行ID(runid)
- 概念:服务器运行ID是每一台服务器每次运行的身份识别码,一台服务器多次运行可以生成多个运行id
- 组成:运行id由40位字符组成,是一个随机的十六进制字符 例如- -
- fdc9ff13b9bbaab28db42b3d50f852bb5e3fcdce
- 作用:运行id被用于在服务器间进行传输,识别身份
- 如果想两次操作均对同一台服务器进行,必须每次操作携带对应的运行id,用于对方识别
- 实现方式:运行id在每台服务器启动时自动生成的,master在首次连接slave时,会将自己的运行ID发送给slave,slave保存此ID,通过info Server命令,可以查看节点的runid
复制缓冲区
- 概念:复制缓冲区,又名复制积压缓冲区,是一个先进先出(FIFO)的队列,用于存储服务器执行过的命 令,每次传播命令,master都会将传播的命令记录下来,并存储在复制缓冲区
- 由来:每台服务器启动时,如果开启有AOF或被连接成为master节点,即创建复制缓冲区
- 作用:用于保存master收到的所有指令(仅影响数据变更的指令,例如set,select)
- 数据来源:当master接收到主客户端的指令时,除了将指令执行,会将该指令存储到缓冲区中
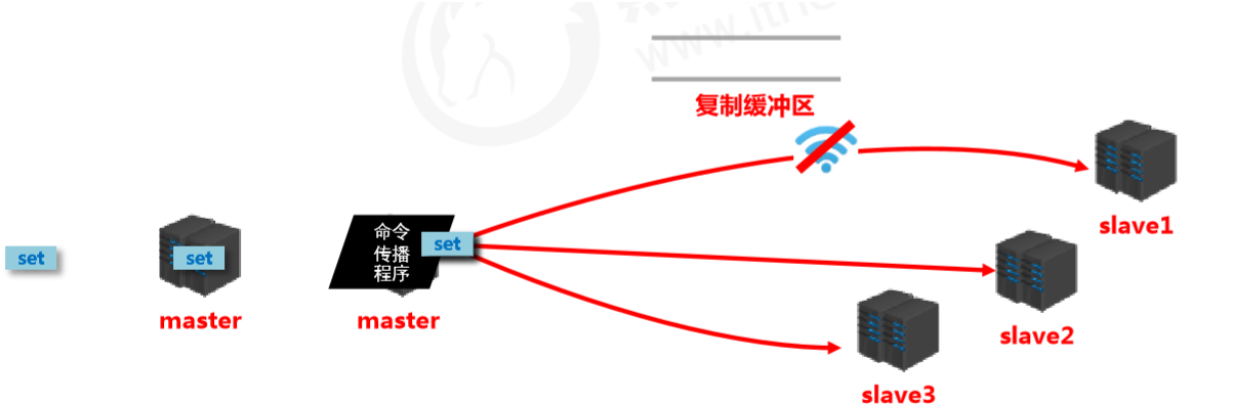
复制缓冲区内部工作原理
-
组成
- 偏移量
- 字节值
-
工作原理
- 通过offset区分不同的slave当前数据传播的差异
- master记录已发送的信息对应的offset
- slave记录已接收的信息对应的offset
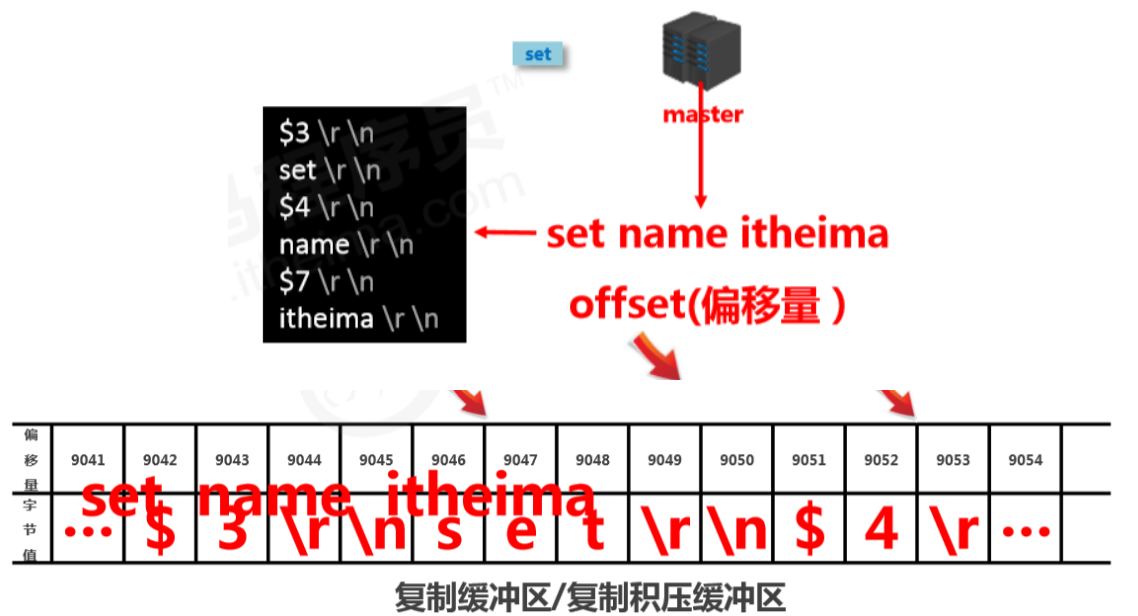
主从服务器复制偏移量(offset)
- 概念:一个数字,描述复制缓冲区中的指令字节位置
- 分类:
- master复制偏移量:记录发送给所有slave的指令字节对应的位置(多个)
- slave复制偏移量:记录slave接收master发送过来的指令字节对应的位置(一个)
- 数据来源: master端:发送一次记录一次 slave端:接收一次记录一次
- 作用:同步信息,比对master与slave的差异,当slave断线后,恢复数据使用
数据同步+命令传播阶段工作流程

心跳机制
- 进入命令传播阶段候,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线
- master心跳:
- 指令:PING
- 周期:由repl-ping-slave-period决定,默认10秒
- 作用:判断slave是否在线
- 查询:INFO replication 获取slave最后一次连接时间间隔,lag项维持在0或1视为正常
- slave心跳任务
- 指令:REPLCONF ACK {offset}
- 周期:1秒
- 作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令
- 作用2:判断master是否在线
心跳阶段注意事项
-
当slave多数掉线,或延迟过高时,master为保障数据稳定性,将拒绝所有信息同步操作
min-slaves-to-write 2 min-slaves-max-lag 8Copy- slave数量少于2个,或者所有slave的延迟都大于等于10秒时,强制关闭master写功能,停止数据同步
-
slave数量由slave发送REPLCONF ACK命令做确认
-
slave延迟由slave发送REPLCONF ACK命令做确认
完整流程

常见问题

频繁的网络中断


数据不一致

九、哨兵
1、简介
哨兵(sentinel) 是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的master并将所有slave连接到新的master。

2、作用
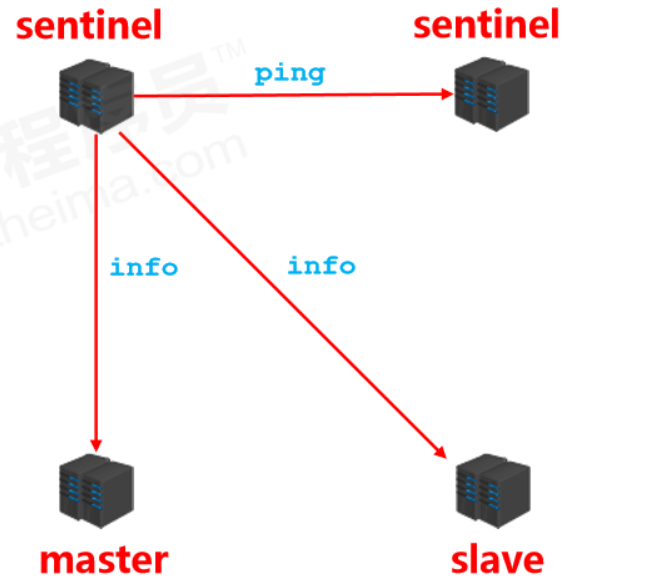
- 监控
- 不断的检查master和slave是否正常运行。 master存活检测、master与slave运行情况检测
- 通知(提醒)
- 当被监控的服务器出现问题时,向其他(哨兵间,客户端)发送通知。
- 自动故障转移
- 断开master与slave连接,选取一个slave作为master,将其他slave连接到新的master,并告知客户端新的服务器地址
注意: 哨兵也是一台redis服务器,只是不提供数据服务 通常哨兵配置数量为单数
3、配置哨兵
-
配置一拖二的主从结构
-
配置三个哨兵(配置相同,端口不同)
- 参看sentinel.conf
-
启动哨兵
redis-sentinel sentinel端口号 .confCopy

4、工作原理
监控阶段
- 用于同步各个节点的状态信息
- 获取各个sentinel的状态(是否在线)
- 获取master的状态
- master属性
- runid
- role:master
- 各个slave的详细信息
- master属性
- 获取所有slave的状态(根据master中的slave信息)
- slave属性
- runid
- role:slave
- master_host、master_port
- offset
- …
- slave属性
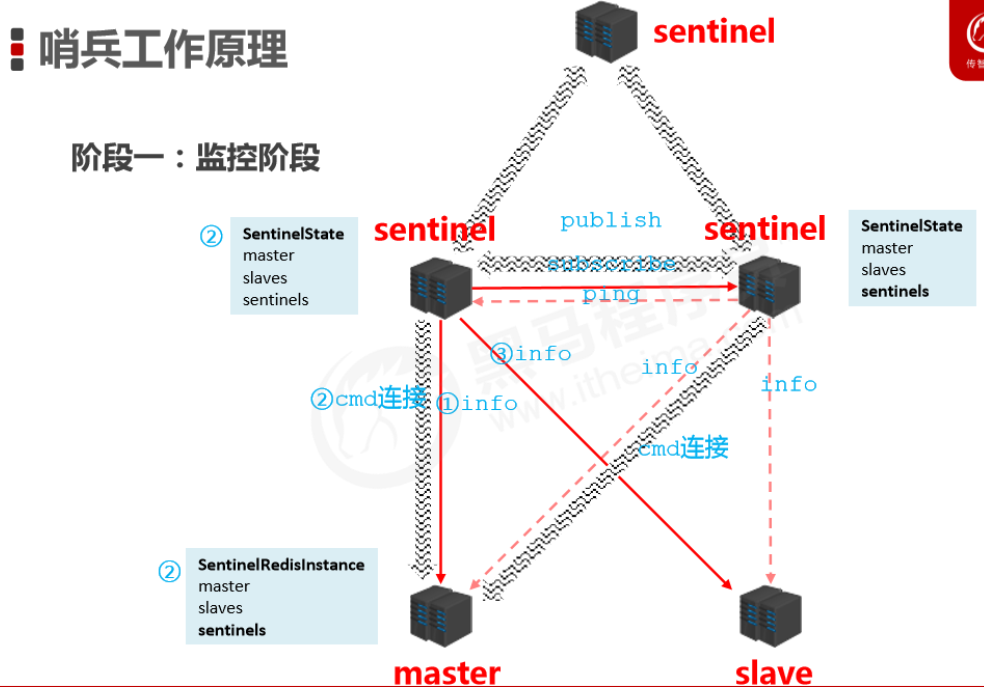
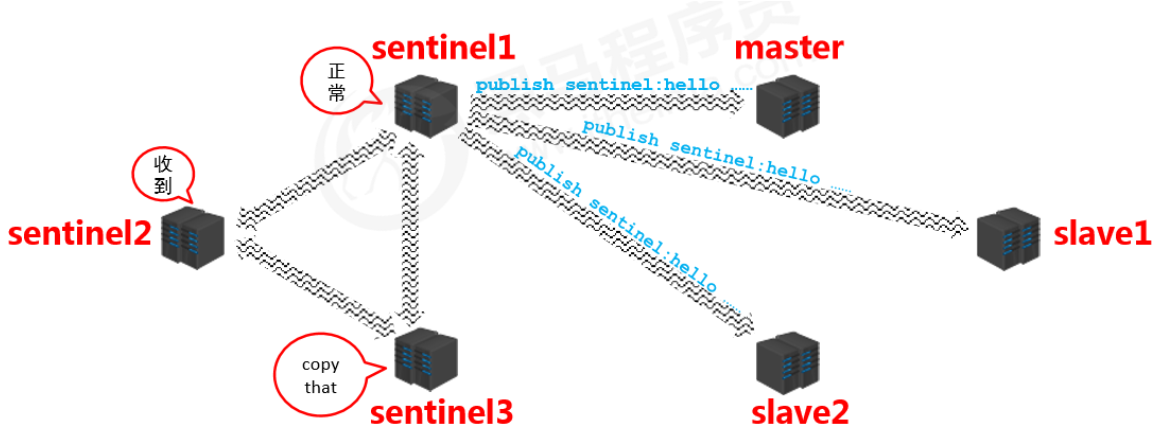
通知阶段
- 各个哨兵将得到的信息相互同步(信息对称)
故障转移
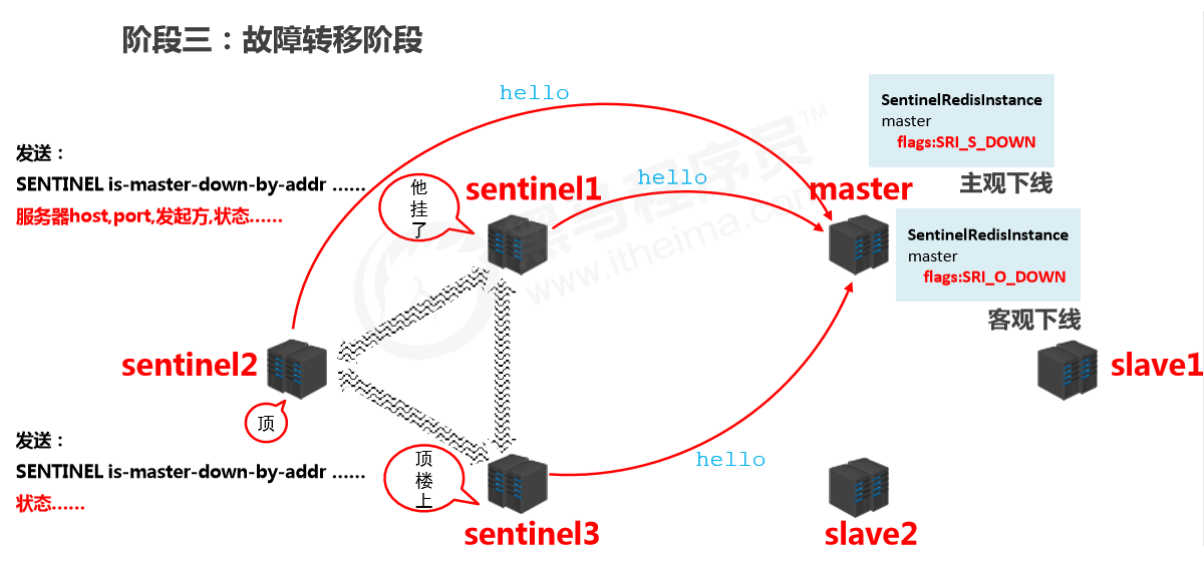
确认master下线
- 当某个哨兵发现主服务器挂掉了,会将master中的SentinelRedistance中的master改为SRI_S_DOWN(主观下线),并通知其他哨兵,告诉他们发现master挂掉了。
- 其他哨兵在接收到该哨兵发送的信息后,也会尝试去连接master,如果超过半数(配置文件中设置的)确认master挂掉后,会将master中的SentinelRedistance中的master改为SRI_O_DOWN(客观下线)
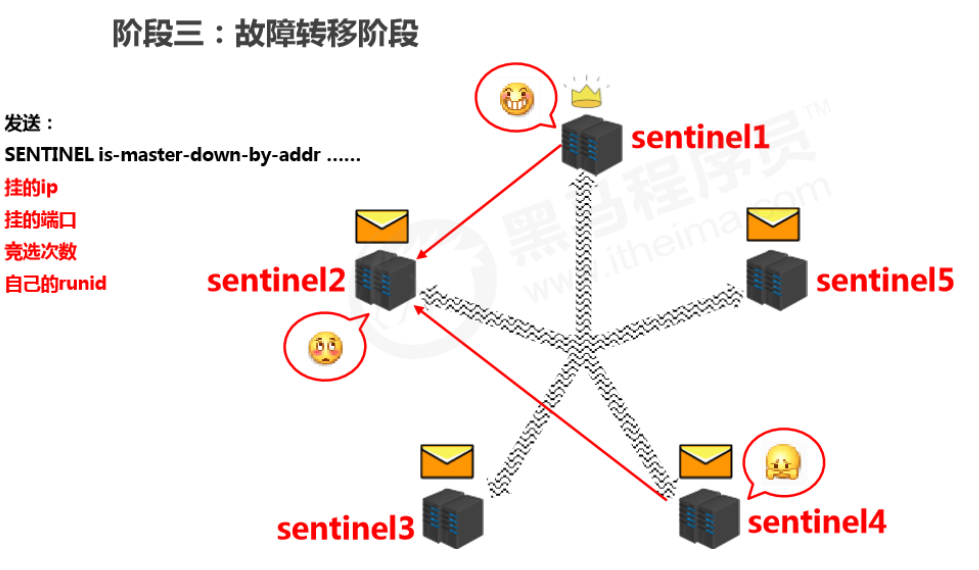
推选哨兵进行处理
- 在确认master挂掉以后,会推选出一个哨兵来进行故障转移工作(由该哨兵来指定哪个slave来做新的master)。
- 筛选方式是哨兵互相发送消息,并且参与投票,票多者当选。
具体处理
- 由推选出来的哨兵对当前的slave进行筛选,筛选条件有:
- 服务器列表中挑选备选master
- 在线的
- 响应慢的
- 与原master断开时间久的
- 优先原则
- 优先级
- offset
- runid
- 发送指令( sentinel )
- 向新的master发送slaveof no one(断开与原master的连接)
- 向其他slave发送slaveof 新masterIP端口(让其他slave与新的master相连)
十、集群
1、简介
集群架构
- 集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果
集群作用
- 分散单台服务器的访问压力,实现负载均衡
- 分散单台服务器的存储压力,实现可扩展性
- 降低单台服务器宕机带来的业务灾难
2、Redis集群结构设计
数据存储设计
- 通过算法设计,计算出key应该保存的位置
- 将所有的存储空间计划切割成16384份,每台主机保存一部分 每份代表的是一个存储空间,不是一个key的保存空间
- 将key按照计算出的结果放到对应的存储空间

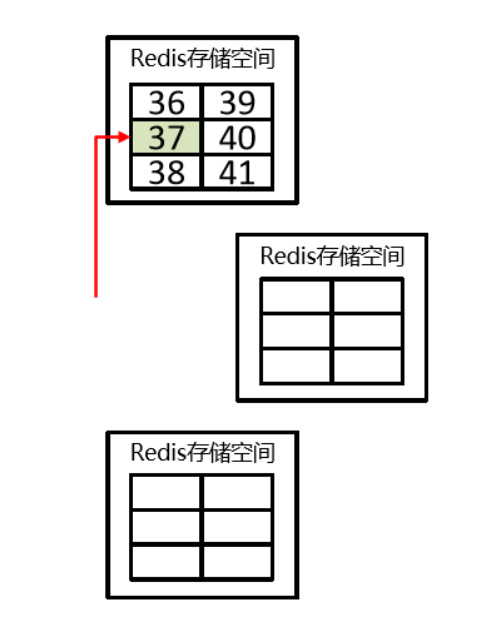
- 增强可扩展性 ——槽

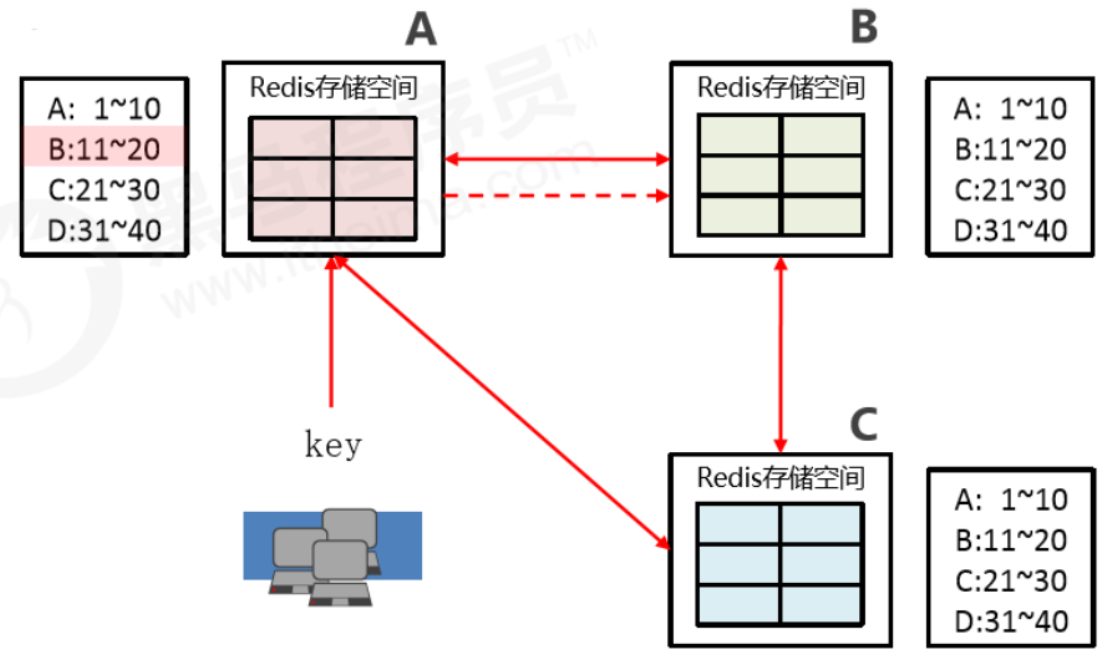
集群内部通讯设计
- 各个数据库互相连通,保存各个库中槽的编号数据
- 一次命中,直接返回
- 一次未命中,告知具体的位置,key再直接去找对应的库保存数据
十一、企业级解决方案
1、缓存预热
问题排查
- 请求数量较高
- 主从之间数据吞吐量较大,数据同步操作频度较高
解决方案
- 前置准备工作:
- 日常例行统计数据访问记录,统计访问频度较高的热点数据
- 利用LRU数据删除策略,构建数据留存队列 例如:storm与kafka配合
- 准备工作:
- 将统计结果中的数据分类,根据级别,redis优先加载级别较高的热点数据
- 利用分布式多服务器同时进行数据读取,提速数据加载过程
- 热点数据主从同时预热
- 实施:
- 使用脚本程序固定触发数据预热过程
- 如果条件允许,使用了CDN(内容分发网络),效果会更好
总结
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
2、缓存雪崩
数据库服务器崩溃(1)
- 系统平稳运行过程中,忽然数据库连接量激增
- 应用服务器无法及时处理请求
- 大量408,500错误页面出现
- 客户反复刷新页面获取数据
- 数据库崩溃
- 应用服务器崩溃
- 重启应用服务器无效
- Redis服务器崩溃
- Redis集群崩溃
- 重启数据库后再次被瞬间流量放倒
问题排查
- 在一个较短的时间内,缓存中较多的key集中过期
- 此周期内请求访问过期的数据,redis未命中,redis向数据库获取数据
- 数据库同时接收到大量的请求无法及时处理
- Redis大量请求被积压,开始出现超时现象
- 数据库流量激增,数据库崩溃
- 重启后仍然面对缓存中无数据可用
- Redis服务器资源被严重占用,Redis服务器崩溃
- Redis集群呈现崩塌,集群瓦解
- 应用服务器无法及时得到数据响应请求,来自客户端的请求数量越来越多,应用服务器崩溃
- 应用服务器,redis,数据库全部重启,效果不理想
问题分析
- 短时间范围内
- 大量key集中过期
解决方案(道)
- 更多的页面静态化处理
- 构建多级缓存架构 Nginx缓存+redis缓存+ehcache缓存
- 检测Mysql严重耗时业务进行优化 对数据库的瓶颈排查:例如超时查询、耗时较高事务等
- 灾难预警机制 监控redis服务器性能指标
- CPU占用、CPU使用率
- 内存容量
- 查询平均响应时间
- 线程数
- 限流、降级 短时间范围内牺牲一些客户体验,限制一部分请求访问,降低应用服务器压力,待业务低速运转后再逐步放开访问
解决方案(术)
- LRU与LFU切换
- 数据有效期策略调整
- 根据业务数据有效期进行分类错峰,A类90分钟,B类80分钟,C类70分钟
- 过期时间使用固定时间+随机值的形式,稀释集中到期的key的数量
- 超热数据使用永久key
- 定期维护(自动+人工) 对即将过期数据做访问量分析,确认是否延时,配合访问量统计,做热点数据的延时
- 加锁 慎用!
总结
缓存雪崩就是瞬间过期数据量太大,导致对数据库服务器造成压力。如能够有效避免过期时间集中,可以有效解决雪崩现象的出现 (约40%),配合其他策略一起使用,并监控服务器的运行数据,根据运行记录做快速调整。
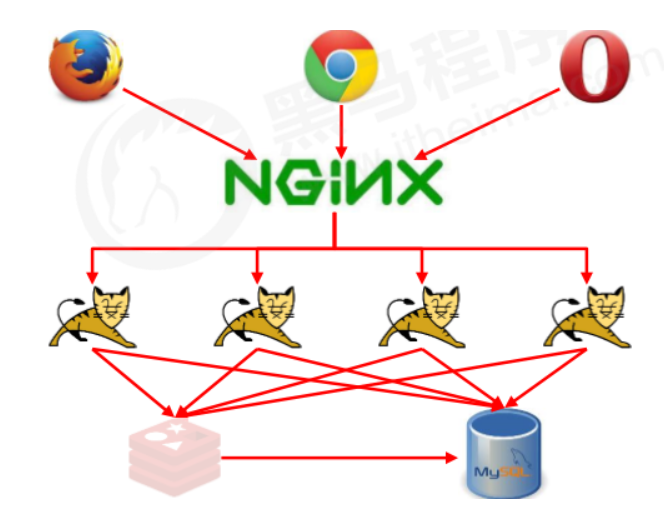
3、缓存击穿
数据库服务器崩溃(2)
- 系统平稳运行过程中
- 数据库连接量瞬间激增
- Redis服务器无大量key过期
- Redis内存平稳,无波动
- Redis服务器CPU正常
- 数据库崩溃
问题排查
- Redis中某个key过期,该key访问量巨大
- 多个数据请求从服务器直接压到Redis后,均未命中
- Redis在短时间内发起了大量对数据库中同一数据的访问
问题分析
- 单个key高热数据
- key过期
解决方案(术)
-
预先设定
以电商为例,每个商家根据店铺等级,指定若干款主打商品,在购物节期间,加大此类信息key的过期时长
注意:购物节不仅仅指当天,以及后续若干天,访问峰值呈现逐渐降低的趋势
-
现场调整
- 监控访问量,对自然流量激增的数据延长过期时间或设置为永久性key
-
后台刷新数据
- 启动定时任务,高峰期来临之前,刷新数据有效期,确保不丢失
-
二级缓存
- 设置不同的失效时间,保障不会被同时淘汰就行
-
加锁 分布式锁,防止被击穿,但是要注意也是性能瓶颈,慎重!
总结
缓存击穿就是单个高热数据过期的瞬间,数据访问量较大,未命中redis后,发起了大量对同一数据的数据库问,导致对数据库服务器造成压力。应对策略应该在业务数据分析与预防方面进行,配合运行监控测试与即时调整策略,毕竟单个key的过期监控难度较高,配合雪崩处理策略即可
4、缓存穿透
恶意请求
我们的数据库中的主键都是从0开始的,即使我们将数据库中的所有数据都放到了缓存中。当有人用id=-1来发生恶意请求时,因为redis中没有这个数据,就会直接访问数据库,这就称谓缓存穿透
解决办法
- 在程序中进行数据的合法性检验,如果不合法直接返回
- 使用布隆过滤器
Ending
终于学完了这13小时的课程,在边学边忘的过程中幸好有笔记的补充。虽然让我学习时间拉长了很多,但是确实非常有帮助,学习不是学完而是反复加深和实操的过程。学习完感觉对reids清晰了一点点,虽然很多功能没机会使用到,但是希望在不久的将来可以有勇武之力,可以更加深层次的体会reids。
资料
本博客所有文章除特别声明外,均采用 @Oreoft 许可协议。转载请注明出处!
┌┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┐
├ 记得关注公众号:没有气的汽水 ┤
└┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┘
