
前言
今天又面了一家比较心仪的公司,除了一些常见的基础考察外,有几个场景设计考察我觉得蛮有意思的,应该是实际项目中业务上能用到的一些设计,因为我现在就职的公司业务对实时性这块没有那么敏感,所以平时中间件的一些特殊玩法没有好好研究,交流的时候也答得不算太好,说了一些自己想法。所以回来特意总结学习一下,确实也非常有意思。
如果防止库存击穿(字段值出现负数)/重复请求幂等性
问怎么保证mysql里面字段值不会出现负值
一般业务里面也经常会有这样的考量,一般共享资源竞争都会在server层就加锁处理。当我撸撸袖子准备讲一下分布式锁的时候,面试官又加了一个限制条件不能在代码里面处理,纯问mysql层面。
第一直觉肯定是先字段先设置无符号的unsigned,这样字段不会变成负数,如果是因为并发请求过来马上要减成负数的时候,mysql会把异常抛出去更新失败,然后再代码里面捕获处理一下就好了。可能这不是面试官想听到的答案,于是他又换了一种问法
如果防止请求多次提交,比如本来只想减少库存100,因为重复请求减少了两次100
当我又撸撸袖子想说HTTP请求幂等性的时候,限定条件又是从db层面去解决问题。我仔细思考了一下,没有思路,就直说不太了解;
回来查了一下资料发现innodb有一个事务的行级锁-for update,我想应该当时面试官希望引导我说出这个,很遗憾公司业务很少用到事务,这块是真的不了解,菜的很板上钉钉。了解后发现这个for update特性确实可以解决很多问题,后面可以在业务里面试试,for update是在事务当中的一把悲观锁,所谓悲观锁就是一种并发控制的思想,当数据要修改的时候,锁会认为一定会产生冲突,所以会保持对资源的独占。innodb锁的粒度是可以到行级的。for update是api,悲观行锁和事务隔离是原理。通过这两个其实很好解决这个问题,在事务当中查询当前库存,然后再扣除100库存,这个update的语句应当把刚刚查询的数量给带上伪代码如下
num = select num from someTable where id = 1
update someTable set num = $num - 100 where id = 1 and num = $num
一般互联网公司的隔离级别都是可重复度,所以这个场景中其他事务的修改不会影响到select的查询结果,当执行update的试试,若果其他事务锁住了这个记录,update会堵塞一下,等待获取锁的事务把锁释放掉,如果该update拿到锁了会执行,但是发现nun已经不等于了,所以不会进行修改这条操作。因为对于select来说读的是“快照数据”,是历史数据,这也是可重复的特性。
那么同理最开始问的那个库存击穿的问题也可以通过这个来搞定。了解下来其实非常有意思,我对内也经常做mysql的技术分享,但是因为自己项目中用事务比较少,对这块的一些特性了解的也很少,还是有点偷懒了。
redis如何实现多字段排序
如何实现一个排行榜,保证性能
我看到保证性能,就知道让我说redis的zset了。但是出于严谨,我还是说了一下,还是要看业务场景,有些场景mysql做的更好,有些场景redis反而没必要,甚至数据量很大的场景只能进行离线计算了(因为我目前就职部门是数据部门,我们这边做离线计算非常熟练了,你要和我说这个我可不困了)。面试官暗示不要和我扯别的,就用redis。那么很容易想到使用sorted set的数据结构。key就可以设置成xxxrank:zset,vaule里面的member就设置成userId, score就设置成排行的权重值。因为score提供incrBy的原子操作,确实挺合适的。因为没开发过用redis的排行榜需求,这个思路也都是在书上看到或者与前辈交流学习到的。接下来的连环问题直接把我问蒙了。
排行榜如果有多个维度来进行排序,类似于mysql的orderby后面多个字段,应该怎么来做
实话就是我脑袋里面没有思路,想了一会我也直说了。回来一查发现,自己实在是太菜了,redis可真的是好玩,居然还是通过zset来做到,虽然zet只能通过score进行排序,但是不一定就是说单字段排序,可以把字段都融合到socre里面,因为大部分需要排序的都是数值型,那么就可以利用数值型和进制的特性来进行排序。
比如两个字段排序,一个是分数,一个是时间;那我在代码里面写入zset的score就可以拼接一下,比如把分数作为整数部分,把时间转化成时间戳作为小数部分(要注意精度)
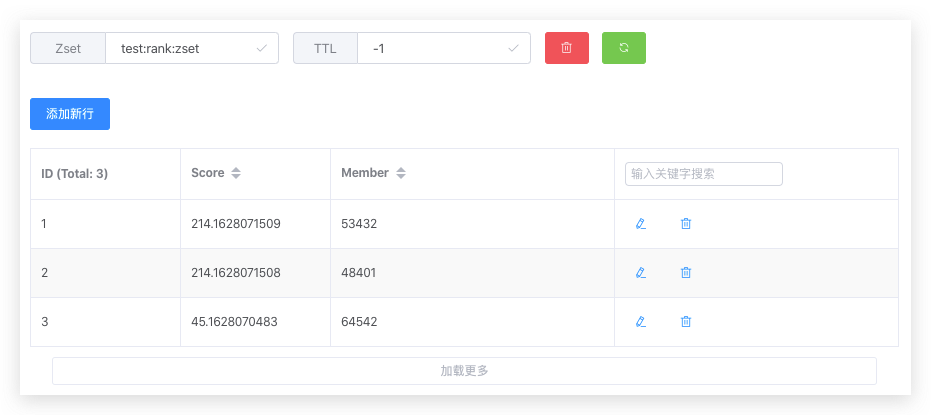
甚至你可以制定好自己的score规则,完成更多的字段排序,这就需要你写入的时候控制好进制位和长度,把权重优先级高一点的字段写入的时候拼接到前面高进制位。
redis的数据结构真的是有很多玩法,我们项目当中有一个zset的应用我觉得也非常有意思,趁着分享一下。
需求是提醒用户需求,用户点击开始计时,表示用户在学习,用户点击结束计时表示用户没有在学习。我需要给学习时长达2小时的用户发送push通知(这部分极光搞定,不用操心),并且如果用户没有下麦每隔两小时就要提醒一下(大概内容就是让它休息休息别学太累了)。
当然解决方法也有很多种,因为设计定时时间所以肯定需要用到定时任务,最蠢的办法就是扫表,表字段里面肯定有开始时间,diff一下开始时间和当前时间是否大于2个小时的毫秒戳。虽然开始时间肯定会建索引,但是开销依然非常大,并且是定时任务有一定的风险加上精读也比较低,最重要的是两个小时后用户没有结束学习,它学到第四个小时你又要提醒,这部分提醒如果扫表去做,又要增加另外的逻辑。
当然最优雅的就是延迟队列去处理,上麦加延迟队列下麦就延迟队列弹出,延迟队列回调的业务里面每次判断它是否还在麦上在的话继续放下一轮延迟队列里面,但是当时太懒了,因为新业务不确定以后这种需求多不多搭建一个比较麻烦(虽然后面还是做了,使用redis的过期回调做的,下次分享)
那么最终我的处理,就是使用zset,上麦的时候把数据放入zset中,member存放userId, score存放当前毫秒戳+2小时毫秒值, 下麦的时候在把这个数据删掉。
然后我再开一个定时任务去访问接口,接口里面rangeByScore把当前时间错和2分钟前时间戳扫出来(定时任务是1分钟扫一次,每次扫前两分钟,留了一分钟容错),然后这些userId都是当前到点需要提醒的。扫出来以后我把数据读到内存里面其实我会立即开管道去回写去更新数据把score更新成当前毫秒戳+2小时毫秒值(供下一个周期的四小时提醒)。
redis如何实现排行榜
如何实现一个排行榜,这个排行榜里面有很多字段
这个问题和上面是耦合在一起的,但是因为问题侧重不一样我就拆开来了。我当时最初的设计是,member存userId,然后score放权重数据。然后zrevrange直接取出来,根据userId再查表组装相应的数据。后来面试官说100个人要再循环查100遍表开销有点大,他这么说是我没想到的…..我再更细描述了一下我的做法,100个userId的话一次使用in放到一个sql里面一次jdbc就搞定。
排行榜里面有很多字段,字段不想再进行查表的开销吗,如何用redis搞定
可能我刚开始就没搞清楚面试官的重点,他这么一解释我就知道了,这题我做不了…..期间我想了一下怎么处理,因为多个字段,可能是想往hash上面引,但是hash不好做排序啊,难道zset的member存放序列化后的json?然后只说不知道认怂了。然后我回来查资料也没找到好的解决方案,把这个问题抛出来,看看大家有没有好的想法。
后言
有时候和一个好的面试官聊天也能收获很多,一般好的面试官都会把自己公司的场景作为对候选人的考察,有时候可以遇到自己业务之外的场景,即便是自己没想出来通过面试官的引导或者回家查资料都能丰富对知识的理解。
就我看来很多场景其实都是开放性的,比如某某场景用很多中间件都可以做到,甚至在这个场景下某种处理是更佳的选择,但是因为面试官想要考察你对一个中间件的理解程度限定了范围。就比如我经常会遇到别人问我缓存和db数据一致性问题,这问题本身就是权衡下才能得出结果的,因为压根就没有silver bullet,我会如是告诉它我们公司线上是怎么处理的,以及我知道的一些处理方式,但是我觉得这些方式都不适用于我们项目的现在流量和并发量,不仅麻烦还可能弄巧成拙。
参考
(转载本站文章请注明作者和出处 没有气的汽水)
┌┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┐
├ 文章已经完啦, 想要第一时间收到文章更新可以关注↓ ┤
└┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┘

Post Directory
下面是评论区,欢迎大家留言探讨或者指出错误哈