
前言
我开发的一个首页提醒推荐接口,需求是今日提醒(推荐)过的内容就不能再提醒了。因为这个提醒内容量级(数量级不会超过用户的好友个数)和数据大小(就是一个userId)都非常小,所以我直接把今日推荐过的历史数据放入redis中进行版本比对。这个方案是没问题的,在生产也跑了一段时间了。
然后还有一个铺垫,就是我们线上的reids使用的是Cluser分片集群的方案,因为我们C端互联网公司对Redis的依赖非常强。如果使用主从的话虽然加机器可以解决流量瓶颈问题,但是每个节点是储存某业务的所有数据,想要提升又要升配。恰好我们流量又大,又重度依赖导致空间占用大。所以不仅要加机器,每台机器的内存还有大…..我们所有服务都是上云的,这个成本非常高。所以我们采用Cluser的方案,所有的Key进来先进行CRC16的散列然后mod一个16384对应一个Hash Solt,最后Cluser再把这16384个Hash Solt进行瓜分。每台Redis实例其实是分配到一定数量的Hash Solt,所有实例加起来才是这个业务全部的缓存数据。
遇到问题
上午客服说有很多用户反馈,会出现重复推荐的情况,这个提醒很打扰。我说不会啊,正常的话是今天被推荐过一次就会去重推荐了(因为我会把记录存到redis中,TTL设置到今晚的23:59:55+随机秒数)。第一时间我在本地debug了一下,拿我自己账号我测试没问题,会进redis,然后下次相同不会提醒了。咦~没问题啊,然后拿同事账号做测试,也不会重复推荐啊。心里想唉用户肯定又开始胡说八道了,让客服给用户回复说我们在观察一下,然后就继续开心摸鱼啦。
下午测试同学拿一个测试手机过来反馈其他问题,我deBug的过程中突然发现上午的Bug居然在这台手机的账号上可以复现,我赶紧用我自己的账号再是一下,发现是正常的。这真的是有意思的,具体的问题如下
当这个测试用户调推荐接口,断点进来一切都正常,最后执行setex后redis里面找不到key。
然后我用我的账号试了一下,手动把redis中我账号对应业务key删掉,然后掉一遍接口,setex后查询对应key,发现key是在的并且TTL正常。
然后我改写代码成非原子性,先set然后再expire,用测试账号调接口,惊人的事情发生了,set后查redis是有值的,但是TTL返回是-1(也就是没有设过期时间),然后代码走完expire再查redis,居然这个key就不见了
说实话,我现在复盘这个场景很快就能推断原因,但都是事后诸葛亮了。但是当时确实想了很多原因,甚至是想要使用Monitor看服务器接受的命令。最后事情发展到不仅仅我这个业务出现这个问题,很多其他业务都遇到了这个问题(因为我们一些业务是共用同一个Cluser)的。
问题的解决
后面实在是折腾了很久,被CTO注意到了,在我们讲了我们遇到的问题以后,老大啪啪啪马上打开redis的运维后台,看到有个结点实例的内存已经是超过了1G。当时我们的cluster规格是64G集群版(32节点),每个节点有一个从节点。所以每个节点可用的容量就是1G.
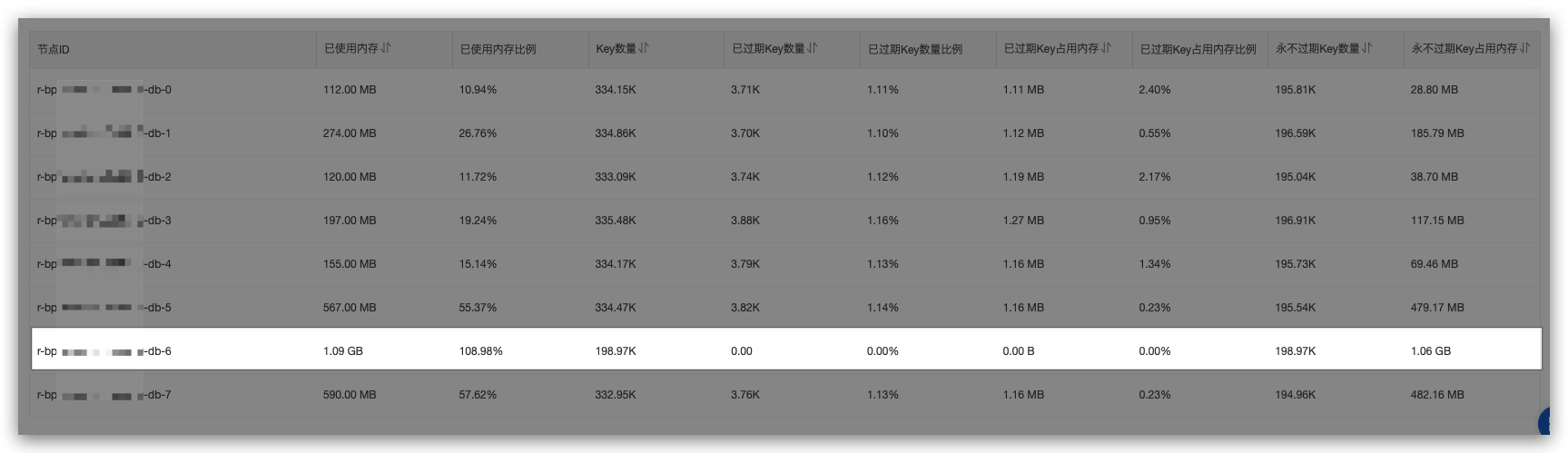
当时推断应该是某些userId的组合成的key被shard到这个节点,但是这个节点已经超过redis配置的内存限制了,并且没有TTL的key也超过了这个内存限制,然后再写入的数据就直接会被淘汰掉。
虽然只是推断,但是我们顺着这个方向解决这个问题,我们使用CloudDBA对这个节点的进行缓存分析,定位这个节点下面整体的数据分布。分析发现其他数据结构都很正常,但是hash结构几乎占用了99%的空间,这明显是不正常的。
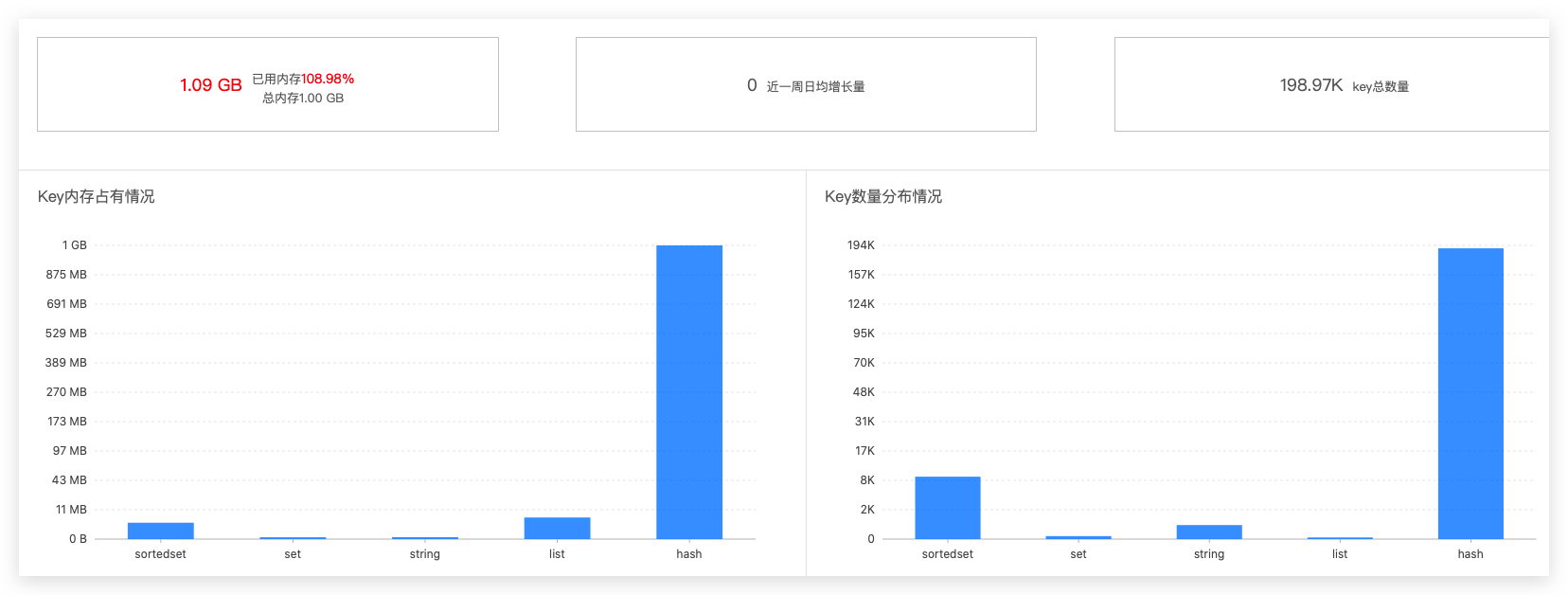
看到这个结果,大概率是有bigKey的产生,紧接着又进行key分析,看是否真的是有bigKey。是技术上没处理好,还是业务上没有打散。最终定位结果是一个记录log的哈希key,单key就占用超过redis的配置上限了。

询问写入这个key的责任人,结果是仅测试环境使用的,上生产的时候忘记删掉了….然后问了下上游其他同事是否用到这个key,发现都没有使用到,然后直接就删掉了。
删掉以后业务恢复正常,这个问题就到此结束了,原因就是我们Redis的架构采用的是Cluster,相当于不同的userId会存储到不同的示例当中,恰好有一个示例容量达到上限,所以被分到这个示例上面的所有userId的key都会出现问题。
事后总结
事后查询阿里云上我们的redis配置,发现配置的就是volatile-lru。这也就解释了,为什么我只要一设置过期时间,这个key就马上被删除。当时真的是陷入了思维定式,总觉得我这个expire命令有问题,没有往这方面想。
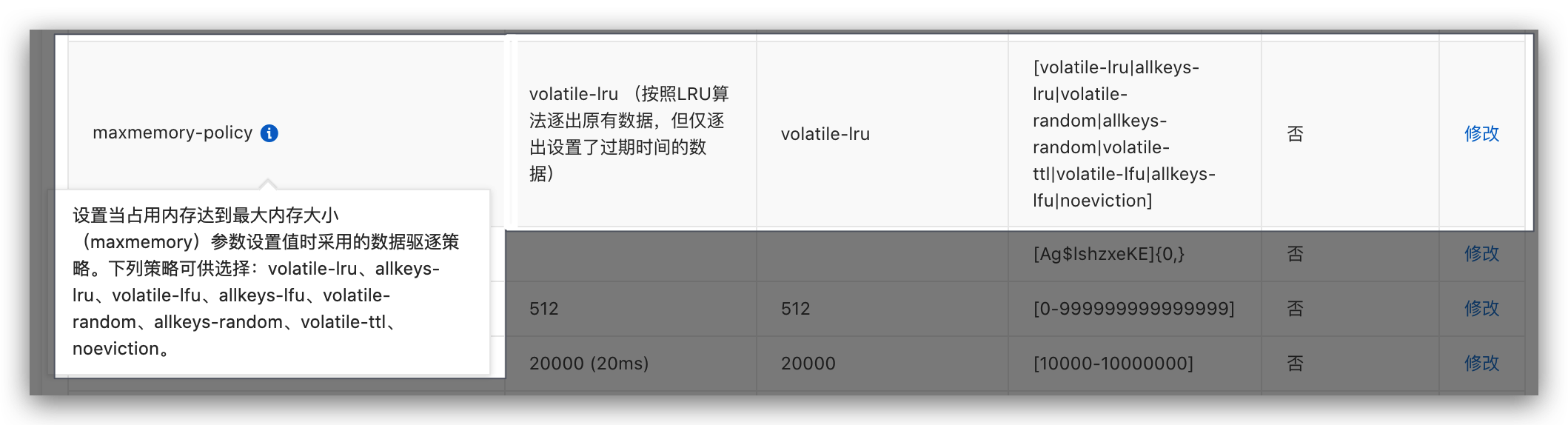
这里复习一下,这八种驱逐策略作为ending(在redis的config中,这个参数名字叫maxmemory-policy)
| 策略 | 解释 |
|---|---|
| VolatileLRU | 按照LRU算法逐出原有数据,但仅逐出设置了过期时间的数据 |
| VolatileTTL | 仅逐出设置了过期时间的数据,并且是按照TTL有小到大的顺序进行逐出 |
| AllKeysLRU | 按照LRU算法逐出原有数据 |
| VolatileRandom | 随机逐出原有数据,但仅逐出设置了过期时间的数据 |
| AllKeysRandom | 随机逐出原有数据 |
| NoEviction(默认) | 不逐出任何数据,新数据的写入会得到一个错误信息 |
| VolatileLFU | 只从设置失效(expire set)的key中选择最不常用的key进行删除 |
| AllkeysLFU | 优先删除掉最不常用的key |
后言
现在来看,如果再发生类似的事情,我可以马上想到应该是节点配置容量达到上限,redis启动了驱逐策略。但是当时如果没有老大的帮忙可能一直都想不到这里去,讽刺的是,这个驱逐策略’八股文’经常背,我陷入了沉思。
因为我一直吐槽这些纸面知识是’八股文’,压根就不如一些编程技巧来的实在。
但是实实在在遇到问题的时候,这理论知识才是你解决实际生产问题的唯一法宝,前提不能单纯的记住,要理解它的作用场景。更应该去编码去模拟去实战,当然有线上的问题可能更加记忆犹新一些(不过成本可能会比较高,hhhhh)。
纸上得来终觉浅,绝知此事要躬行
(转载本站文章请注明作者和出处 没有气的汽水)
┌┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┬┐
├ 文章已经完啦, 想要第一时间收到文章更新可以关注↓ ┤
└┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┴┘

Post Directory
下面是评论区,欢迎大家留言探讨或者指出错误哈